Newton's method for approximate solution to
nonlinear equations
Let us consider a nonlinear function $y(x)$ of a single variable $x$.
We wish to find an approximate numerical solution to the equation $f(x)=0$
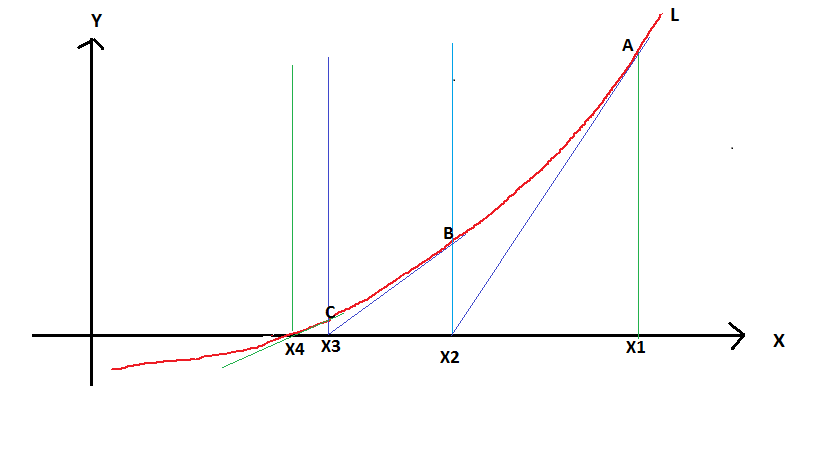
Newton's method provides a simple algorithm for this purpose. The method is pictorially depicted in Figure-1
below:
Let L be the nonlinear curve described by the function $y=f(x)$.
1. Choose a starting point $x = x_1$.
2. Draw the tangent to the curve at $x=x_1$. Let it meet the X axis at $x = x_2$.
3. Draw a tangent to the curve at $x = x_2$. Let it met the X-axis at $x = x_3$.
4. Now draw a tangent to the curve at $x = x_3$. Let it meet the X-axis at $x = x_4$.
5. If Y axis of this point $y(x_4)$ is sufficiently close to zero, then $x=x_4$ is the root of the function.
6. Else, continue same procedure until we hit a $x_n$ for which $y(x_n)$ is sufficiently
close to zero.
The algorithm is very simple. We perform the Taylor series expansion of f(x) at $x=x_0$ to
retain the the first term:
$f(x)~=~f(x_0)~+~f'(x_0)(x-x_0) $
This is the equation of tangent to the curve at $x=x_0$. When this tangent meets the Y-axis
at $x=x_1$, we can write the above equation as,
$0~=~f(x_0)~+~f'(x_0)(x_1 - x_0) $
From this we write
$x_1 ~= x_0~-~\dfrac{f(x_0)}{f'(x_0)} $
When the tangent drawn at $x = x_1$ meets the Y-axis at $x = x_2$, the relation becomes,
$x_2 ~= x_1~-~\dfrac{f(x_1)}{f'(x_1)} $
Similarly,$~~~~~~~x_3 ~= x_2~-~\dfrac{f(x_2)}{f'(x_2)} $
We thus march the solution from starting point $x=x_0$ through $x_1, x_2, x_3, ..., x_n$ until
$y(x_n)$ is arbitrarily close to zero to the extend desired by us.
This give $x = x_n$ as the root of the function f(x).
The general form of the algorithm is
$\large{x_{i+1} ~= x_i~-~\dfrac{f(x_i)}{f'(x_i)} }$
Newton's method is often used to solve two types of problems:
1.
Finding the root of a function: find x such that F(x)=0. For this we use
${x_{i+1} ~= x_i~-~\dfrac{F(x_i)}{F'(x_i)} }$
2.
Find x that minimizes the function L(x). For this, we use the first and second derivatives:
${x_{i+1} ~= x_i~-~\dfrac{L'(x_i)}{L''(x_i)} }$
Applying Newton's method for nonlinear least square minimization
In nonlinear least square minimization, we minimize a function f with respect to p coeffcients named $b_1, b_2, b_3,...,b_p$. The function f is given by,
$f(b_1,b_2,b_3,...,b_p)~=~\dfrac{1}{2} \displaystyle\sum_{i=1}^n r_i^2 $
with
$ r_i~=~[y_i~-~g(b_1,b_2,b_3,....,b_p;~~x_{i1},x_{i2},x_{i3},....,x_{im}] $
where g is the nonlinear function to be minimized, and $x_{i1},x_{i2},x_{i3},....,x_{im}$ are the values of independent variables for data point i.
We introduce the following matrices to represent various quantities in our iteration:
\begin{equation}
{\large\bf\overline b}=
\begin{bmatrix}
b_1 \\
b_2 \\
b_3 \\
... \\
... \\
b_p
\end{bmatrix}
~~~~~~~~~~
{\large\bf\overline b}^{~k}=
\begin{bmatrix}
b_1^k \\
b_2^k \\
b_3^k \\
... \\
... \\
b_p^k
\end{bmatrix}
~~~~~~~~~~
{\large\bf\overline b}^{~k+1}=
\begin{bmatrix}
b_1^{k+1} \\
b_2^{k+1} \\
b_3^{k+1} \\
... \\
... \\
b_p^{k+1}
\end{bmatrix}
~~~~~~~~~~
{\large\bf\overline \nabla f}=
\begin{bmatrix}
\dfrac{\partial f}{\partial b_1} \\
\dfrac{\partial f}{\partial b_2}\\
\dfrac{\partial f}{\partial b_3}\\
... \\
... \\
\dfrac{\partial f}{\partial b_p}
\end{bmatrix}
\end{equation}
where ${\large\bf\overline b}^{~k}$ and ${\large\bf\overline b}^{~k+1}$ are the coefficient matrices in iterations k and k+1 respectively.
In the Gradient descent method, the iterative procedure to determine the coefficients was defined as,
\begin{equation}
\large { {\overline b}^{~k+1}~=~ {\overline b}^{~k}~+~\lambda {\overline \nabla} f(\overline b) }
\end{equation}
$~~~~~~~~~(1)$
In Newton's method, we perform a Taylor expansion of the gradient ${\overline \nabla} f(\overline b)$ around $\overline{b}^k$, a set of b
values obtained in interation k:
$ {\overline \nabla} f(\overline{b})~=~{\overline \nabla} f(\overline{b}^{~k})~+~ (\overline{b} - \overline{b}^{~k})^{T}~{\overline \nabla}^2 f(\overline{b}^{~k})~+~$ (higher order terms)
Neglecting the higher order terms, we write
$ {\overline \nabla} f(\overline{b})~=~{\overline \nabla} f(\overline{b}^{~k})~+~ (\overline{b} - \overline{b}^{~k})^{T}~
{\overline \nabla^2} f(\overline{b}^{~k})$
The coefficients ${\overline b}$ are minimized when the gradient of f is zero. Setting the Left Hand Side of above equation to zero, we get
$\overline{b}~=~\overline{b}^{~k}~+~({\overline\nabla}^2 f(\overline{b}^{~k}))^{-1}~{\overline\nabla} f(\overline{b}^{~k}) $
Taking the second derivative values ${\overline b}^{~k+1}$ to be the neighbourhood point $\overline{b}$, we get
the expression for iterative procedure in Newton's method:
\begin{equation}
\overline{b}^{~k+1}~=~\overline{b}^{~k}~+~({\overline \nabla}^2 f(\overline{b}^{~k}))^{-1}~{\overline\nabla} f(\overline{b}^{~k})
\end{equation}
$~~~~~~~~(2)$
Here we recollect that ${\overline\nabla} f(\overline{b})$ is the gradient matrix and ${\overline \nabla}^2 f(\overline{b})$ is the (second derivative) Hessian matrix.
In Newton's method, we expand the gradient ${\overline \nabla}f(\overline{b})$ around a point using Tayloe expansion. We then neglect the higher order terms. By neglecting the higher order terms we assume that the function f is quardratic around the point of expansion. We then solve for ${\overline \nabla}f(\overline{b})=0$
to get the updated points
The advantages of Newton's method are:
When the function f is quadratic, the method converges in one step.
For nonlinear least square minimization, the method converges quadratically to a local minimum of the initial guess of the parameter value is close enough.
The main disadvantage of this method is that the search direction may not be the descend direction.
Another disadvantage of this method is the requirement that we should conpute second partial derivatives for Hessian matrix. This can be very painful for
functions which are not in simple form. This issue is tackled in Gauss-Newtom method, which uses Jacobians rather than Hessian second derivative matrix to
update. This method guarantees that the search direction is the descend direction.