CountBio
Mathematical tools for natural sciences
Basic Statistics with R
Introduction to hypothesis testing
The data points obtained from repeating an experiment or observation are assumed to have randomly sampled from a parent population (also called as "parent distribution" or simply "population"). From this sample data, we compute the sample parameters like sample mean, sample variance, etc. Even before performing an experiment, we would come up with few statements on the population based on our prior knowledge about it. We belive that these statements are possibly true, and decide to perform experiments to test their validity. A statement on the population believed to be possibly true is called a hypothesis. Generally a hypothesis concerns the parameters of a population. For example, we want to compare the yields of two varieties of rice. Based on some prior knowledge, we make a hypothesis that the mean yield measured in units of Kg per acre of the two varieties are equal under some conditions. This is a statement on their population means. We then plant the two varities on a large area divided into many one acre patches and get their mean yields under the same conditions of our assumption. These sample means can then be used to check the validity of our hypothesis on the equality of the population means. This is how we can test our hypothesis. We will illustrate the methodology of hypothesis testing with the following example: An agricultural farm has been growing and selling medium sized pumpkins for many years. They have been measuring and noting down the weight of each pumpkin they harvested before sending it to the market. Using the mesurements on a very large number of pumpkins over a long period of time, they estimate their mean weight to be \(\small{2.35~Kg}\) with a standard deviation \(\small{0.36~Kg}\). Now the form wants to test a new manure from a fertilizer company which is supposed to increase the yield of pubpkins significantly. To test this claim, the following experiment was devised. One fraction of the pumpkin plants in the farm were treated with the new manure and the other plants were grown with the ususal fertilizer. At the end of the season, 100 pumpkins that grew with new manure were harvested and their mean weight was measured to be \(\small{2.46~Kg}\). From this data, can we say whether the use of new fertilizer has considerably increased the pumbkin weight? What number we will use for this? We will make use of the central limit theorem to analyse this data. Suppose we assume that the weight of the particular variety of pumpkin that has been grown all these days in the farm without manure follows a Normal distribution with a mean \(\small{2.35~Kg}\) and a standard deviation of \(\small{0.36~Kg}\). Since the this mean and its standard deviation were estimated using very large number of pumpkin samples, we approximately take these values to be the population parameters. We also assume that the manure has not at all improved (changed) the yield of pumpkin when compared to yields of previous ones without menure. Then, the 100 pumpkins grown with manure are also can be considered to be the random samples from the above mentioned gaussian whose population mean is \(\small{\mu = 2.35~Kg}\) and standard deviation \(\small{\sigma = 0.36~Kg}\). The estimated mean (sample mean) of these 100 pumpkins turns out to be \(\small{\overline{X} = 2.46~Kg }\). This is the mean weight of 100 random samples from our Gaussian distribtuion. We know that this sample mean \(\small{\overline{X} }\) should follow a Normal distribution according to central limit theorem. Thus we can write, \(\small{Z = \dfrac{\overline{X} - \mu}{\left(\dfrac{\sigma}{\sqrt{n}}\right)} = N(0,1) ~~ }\) a unit normal distribution. Substituting \(\small{\overline{X} = 2.46 }\), \(\small{\mu = 2.35 }\), \(\small{\sigma = 0.36 }\) and \(\small{n = 100 }\) in the above expression for Z, we get \(\small{Z = \dfrac{2.46 - 2.35}{\left(\dfrac{0.36}{\sqrt{100}}\right)} \approx 3.055 }\) Since Z follows a unit normal distribution, the probability of having \(\small{Z > 3.055 }\) is same as the probability of having a weight greater than \(\small{2.46~Kg }\) in a Normal distribution with mean \(\small{\mu = 2.35~Kg}\) and standard deviation \(\small{\sigma = 0.36~Kg}\). The R function call 1 - pnorm(3.055) returns this probability to be 0.001125 . What does this probability 0.001125 mean?. Under the assumption that the new menure does not increase the yield (ie., yield remains same as before), the probability that the mean yield of 100 random samples (grown on menure) can be greater than \(\small{2.46~Kg }\) is 0.001125. We take 100 random samples and find the mean. If we repeat this experiment 1000 times, approximately once we will get a mean value greater than 2.46 Kg (or, equivalently, Z > 3.055). Thus, under the assumption of menure having no effect on yield, the chance probability of getting the observed mean of 2.46 with 100 random samples from a Normal distribution \(\small{\mu=2.35, \sigma=0.36 }\) is 0.001125. Suppose we declare that this chance probability of 0.001125 ( a probability of approximately 1 in 1000) to be very small. This implies that the event in which our 100 samples giving a mean yield of 2.46 Kg by chance is rare. This in turn implies that the increase in mean yield from expected parent mean of 2.35 Kg to the observed 2.46 Kg may be due to the action of new manure. This is not directly proved. The rarer the chance of occurance by nature, more probable that it is due to the other cause. To conclude, we have demonstrated the following in our experiment: We knew that the yield follows a Gaussian with a given mean and sigma. Under the assumption of no effect, the probability of observing the sample mean in this Gaussian distribution is 0.001125, which we feel is very small, and hence a rare event. Therefore, within this definition of rarity, we conclude that the observed mean of 100 samples support the idea that the menure has increased the yield considerably to a level which is not easy to observe normally by chance in the parent distribution. This fact is against our assumption that the manure does not affect the yield. This is the conclusion of this statistical analysis and we are yet to prove this using biochemistry of the menure mechanism and pathway or other biological analysis!.
The steps of hypothesis testing
The whole exercise described above is called hypothesis testing . We will now formally describe the steps with technical terms.
1. Data collection : The first step is to collect the data from the experiment. In this case, the weights of 100 randomly selected pumpkins grown with new manure is the data. We also collect the additional information that the population mean is \(\small{2.35~Kg }\) with a standard deviation of \(\small{0.36~Kg. }\)
2. Assumptions on data and the underlying distribution : We make several assumptions about the nature of the data. Sometimes, the methods of analysis depends of these assumptions. For example, we
want to make sure that the data points within a data set are independent. We also should know whether the two data samples we compare are dependent or independent samples. Also, we should make a reasonable assumption on the nature of the distribution of the population from which the data points are assumed to have been randomly drawn during the experiment. We should also make assumptions about the equality of means and variances, if we compare more than one distribution.
In the current problem, we assumed that the weights of individual water melons are independent, and follow a Gaussian distribution with mean and standard deviation based on very large number of samples. How do we know that the weights follow Gaussian?. We might plot a histogram of very large number of water melons to verify this. Even if the distribution is not exactly Gaussian, we can make use of central limit theorem to get a probability. If the sample sizes are not large enough to study the distribution, we can use standard ststistical tests (like Kolomogorov-Smirnov test) to verify whether the samples come from a Gaussian.
2. State the hypothesis : In the above analysis, we wanted to find out whether the new manure increase the yield. We set about testing the statement that "the menure does not increase the yield". This is called a null hypothesis which is generally a hypothesis of
The one sided and two sided hypothesis
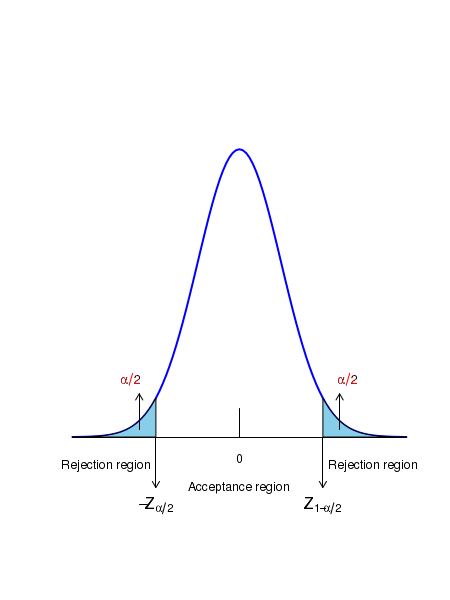
The rejection region in a hypothesis testing is decided by the question asked for the test. In general, there are three types of questions: 1. Can we conclude from the test that \(\small{\mu \neq \mu_0? }\) In this case, the null and alternate hypothesis are given by, \(~~~~~\small{H_0~:~\mu = \mu_0 }~~~~~~~~and~~~~~~~~~\) \(~~~~~\small{H_A~:~\mu \neq \mu_0 }\) The null hypothesis can be rejected by the values of statistic which are much larger than or much smaller than \(\small{\mu_0}\). In this case, the rejection region is split into two, one on each end of the ditribution. Therefore, for a given significance of \(\small{\alpha}\), we choose two rejection regions, one on each tail such that the rejection area on each will be \(\small{\dfrac{\alpha}{2} }\). This is called two sided test . The acceptance and rejection regions of a two sided test are shown in the figure below:
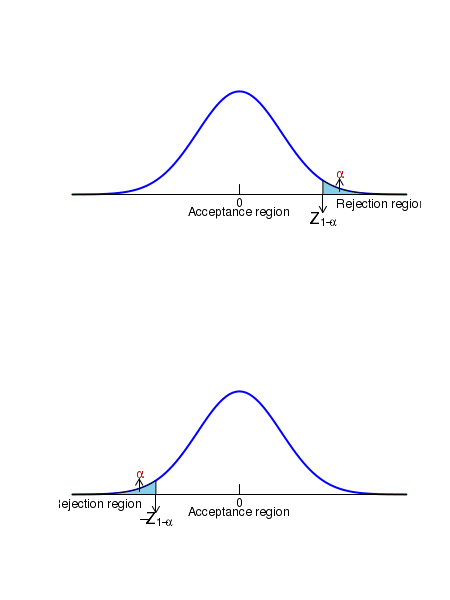
2. Can we conclude from the test that \(\small{\mu \gt \mu_0? }\) The null and alternate hypothesis are, \(~~~~~\small{H_0~:~\mu \leq \mu_0 }~~~~~~~~and~~~~~~~~~\) \(~~~~~\small{H_A~:~\mu \gt \mu_0 }\) In this case, the null hypothesis is rejected by the sufficiently large values of the statistic. The whole of the rejection region will be on the higher end of the distribution tail with area \(\small{\alpha}\). This is also a one sided hypothesis testing . 3. Can we conclude from the test that \(\small{\mu \lt \mu_0? }\) In this case, the null and alternate hypothesis are given by, \(~~~~~\small{H_0~:~\mu \geq \mu_0 }~~~~~~~~and~~~~~~~~~\) \(~~~~~\small{H_A~:~\mu \lt \mu_0 }\) This null hypothesis can be rejected by values of statistic which are sufficiently smaller. In this case, the whole rejection region is at one end of the distribution tail, with area \(\small{\alpha}\). This is also a one sided hypothesis testing . The firgure below shows the regions of rejection for the one sided hypothesis testing: